CouchDB as a State Database in Hyperledger Fabric
In this article, I’ll explain the importance of CouchDB as a State Database in Hyperledger Fabric.

Introduction
Hyperledger Fabric uses state databases to store the ledger records in the World State. The State Database includes LevelDB and CouchDB to be flexible for the developer to verify the records. LevelDB stores the records in key-value pair whereas CouchDB stores records in JSON format with the rich query to the data collection. Since both state databases maintain key-based mapping to the records, thus the keys can be utilised to query by the specific range and can create a composite key to modelled among various parameters.
Composite Key
For example, there is a data set of large employee records of multiple companies. Each employee record stores Name, Email, Company, Occupation, Salary.
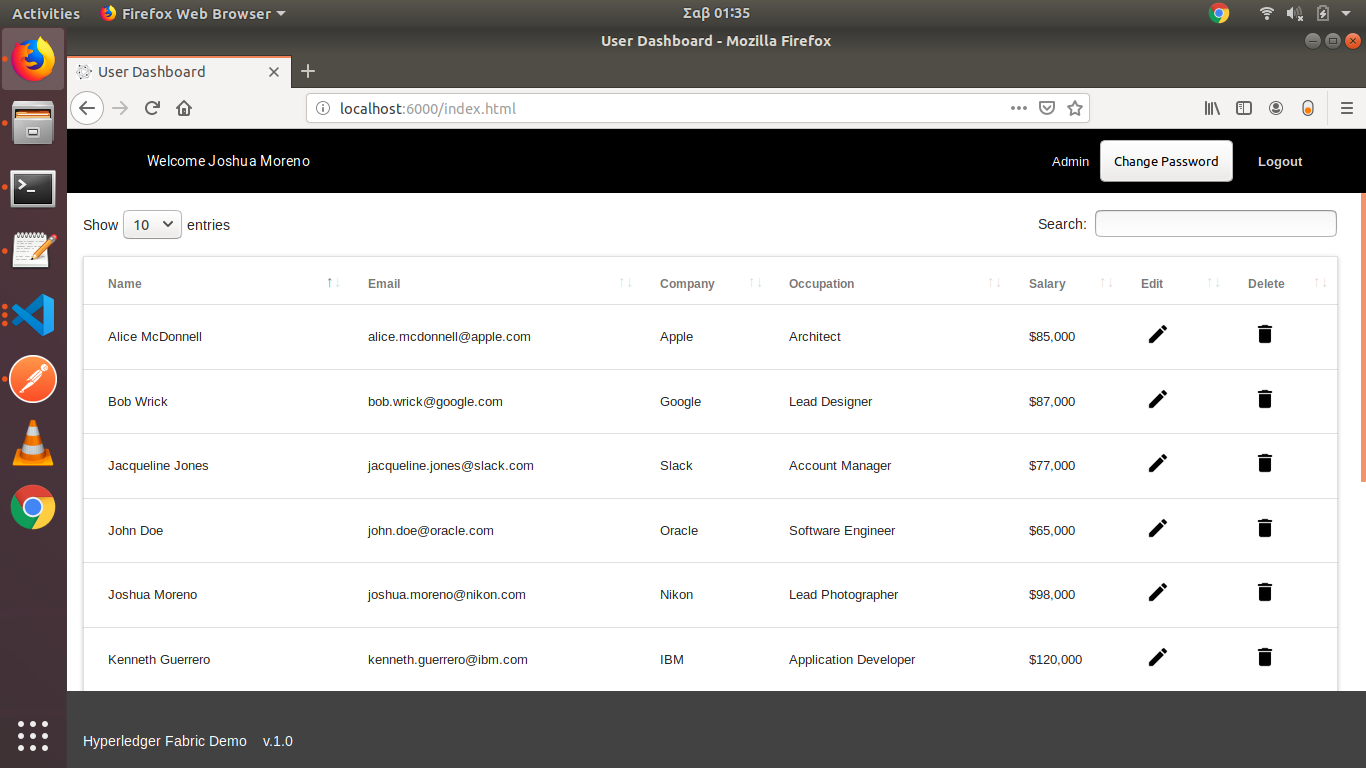
For example — The employee John Doe records needs to be queried among all records. So, we will create the composite key with email which map as unique key for John Doe record.
Why CouchDB?
The key-value pair based indexed data-store is less efficient compared to JSON based collection model against large data set. CouchDB is essentially a JSON document based collection database. The rich query maintains flexibility and enables scalability state database in the blockchain network. The developer must choose among LevelDB or CouchDB from the beginning Since Hyperledger Fabric doesn’t support moving from LevelDB to CouchDB once the network is deployed.
Installing CouchDB in Hyperledger Fabric
CouchDB operates in a docker container, so for installing CouchDB for your network, you need to download CouchDB docker images. In docker-compose.yaml developer needs to define the fabric-couchdb images to download and to create a docker container for CouchDB.
The docker-compose command will download the required CouchDB images for the docker container.
docker-compose up -d
What is CouchDB Index?
CouchDB is efficient in performing a rich query against JSON documents. There is an added advantage by creating indexing JSON files to make CouchDB query even more accurate. If the developer creates a CouchDB index when the collection query doesn’t need to iterate all row and records, that can instantly map with the particular record. Indexing is enormously helpful in case complex and large data set.
For Example -
for this employee record model, if there will be 100,000+ data collection, then it’s quite challenging to perform complex queries from CouchDB.
Queries
- Find employees with occupation “Software Engineer”.
Index JSON :
So, here the collection will map with only “occupation” field and will return with a list of “Software Engineer” of all companies.
2. Find employees with a maximum salary of a certain occupation
Index JSON :
In this index, the query will be minimized to “salary” and “occupation” fields to return with maximum salary input per occupation. For example list employees with occupation “Account Manager” and with maximum salary “$60,000”.
3. Find employees of a company with “Manager” occupation with a maximum salary.
Index JSON :
In this index, the query will sort particular result with “salary”, “occupation” for a “company”. So, these kinds of queries are time-consuming in case of large data set but doing indexing the performance will be faster and accurate.
Packaging Index in Chaincode
The finalized indexEmployee.json will be stored inside “META-INF/statedb/couchdb/indexes/” and “META-INF” folder will be located at chanicode path. The developer can package the indexes either during installation or instantiation of chaincode.
Verify CouchDB index deployed
The indexes will be deployed into each peer’s CouchDB state database. As CouchDB will run in a docker container, to verify the deployment, we can use docker peer logs.
docker logs peer0.org1.employee.ledger.com 2>&1 | grep "CouchDB index"output
[couchdb] CreateIndex -> INFO 0be Created CouchDB index [indexOwner] in state database [mychannel_employeeledger] using design document [_design/indexOwnerDoc]Conclusion
CouchDB is efficient and flexible to design the JSON model to all sort of data collection. The indexing technique makes particular query even further accurate and faster, However, indexing is not that necessary to deploy in all data collection but becomes extremely handy against huge data set involving complex queries.
So, this is the general overview of CouchDB as a State Database in Hyperledger Fabric.
I hope you find this article useful -:)
Thanks
